LLMC
Nov 26, 2024
·
1 min read
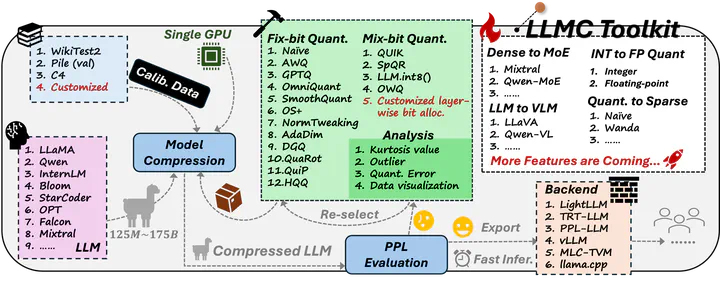
An off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance
An off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance