LightLLM
Jan 27, 2024
·
1 min read
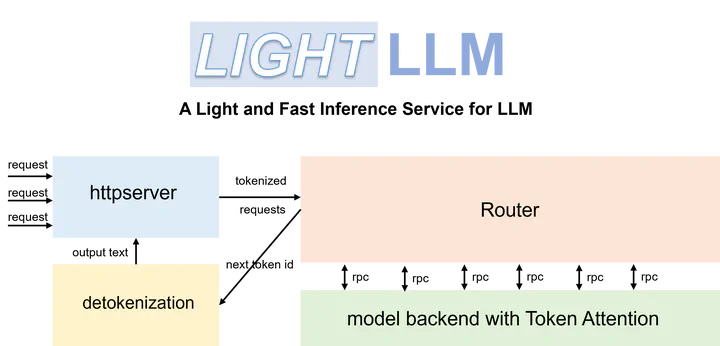
A Python-based LLM inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance.
A Python-based LLM inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance.